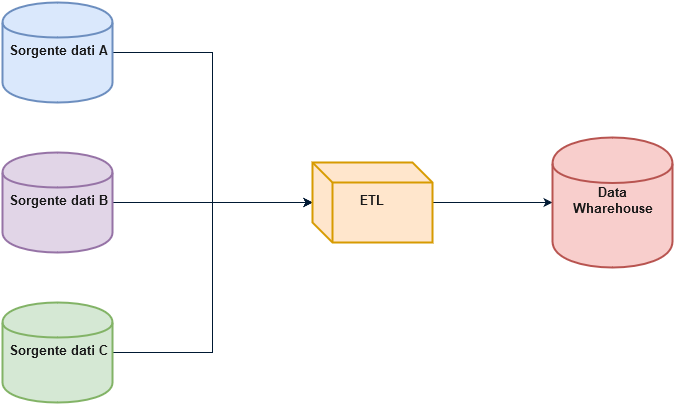
MySql with Docker
Running a MySQL database in a Docker container is straightforward. Here are the steps: Pull the Official MySQL Image: The official MySQL image is available on Docker Hub. You can choose the version you want (e.g., MySQL 8.0): docker pull mysql:8.0 Create a Docker Volume (Optional): To persist your database data, create a Docker volume or bind mount. Otherwise, data will be lost when the container restarts. Example using a volume: docker volume create mysql-data Run the MySQL Container: Use the following command to start a MySQL container: docker run --name my-mysql -e MYSQL_ROOT_PASSWORD=secret -v mysql-data:/var/lib/mysql -d mysql:8.0 Replace secret with your desired root password. The MySQL first-run routine will take a few seconds to complete. Check if the database is up by running: docker logs my-mysql Look for a line that says “ready for connections.” Access MySQL Shell: To interact with MySQL, attach to the container and run the mysql command: docker exec -it my-mysql mysql -p...