Requirements analysis:
Requirement defined: The core function of a help desk is to handle incidents and service
requests. Help desks aim to provide a quick fix to issues users face by handling a request through its life
cycle and returning the service to its normal state as soon as possible. Help desks most often offer basic
incident and problem management capabilities with SLAs, self-service capabilities and knowledge base.
It allows end users to raise tickets and receive support.
Requirement defined: The core function of a help desk is to handle incidents and service
requests. Help desks aim to provide a quick fix to issues users face by handling a request through its life
cycle and returning the service to its normal state as soon as possible. Help desks most often offer basic
incident and problem management capabilities with SLAs, self-service capabilities and knowledge base.
It allows end users to raise tickets and receive support.
Proposed modules:
•Incident/Request/ Problem management
o Manage the life cycle of incidents or service requests raised by end users.
Change management
Service level monitoring and management
Service catalogue
Knowledgebase & Self-service capabilities
i. Allow users to resolve common issues on their own and reduce the help desk workload.
Asset management
i. Manage any documentation including screenshots, etc.
Reporting
End-user surveys
•Incident/Request/ Problem management
o Manage the life cycle of incidents or service requests raised by end users.
Change management
Service level monitoring and management
Service catalogue
Knowledgebase & Self-service capabilities
i. Allow users to resolve common issues on their own and reduce the help desk workload.
Asset management
i. Manage any documentation including screenshots, etc.
Reporting
End-user surveys
Incident/Request/ Problem management
o Manage the life cycle of incidents or service requests raised by end users.
Change management
Service level monitoring and management
Service catalogue
Knowledge base & Self-service capabilities
i. Allow users to resolve common issues on their own and reduce the help desk workload.
Asset management
i. Manage any documentation including screenshots, etc.
Reporting
End-user surveys
Key considerations for the solution
Help desk adds value by helping organization better manage customer experience. Here are some
key considerations while developing the solution:
•
Automation
i. Ticket creation
ii. Automatic escalation based on ticket types and SLAs
Automatically assign tickets to technicians
iv. Automated password reset service
v. Workflow automation
vi. Automatic notifications for requesters and technicians
Security
i. Role-based access permissions
ii. Secure communication with data encryption
iii. Audit logs
Single point of contact
i. An IT support ticket system converges all inbound communication and converts the help
desk into a single point of contact for all customer queries/ requests.
Centralization
i. All data, requests, queries, and tickets are centralized in one place, which makes it easier
to access and manage them.
Efficiency
i. With well-defined workflows and processes, help desk support software helps eliminate
redundant tasks and boosts efficiency.
Continuity
i. With the right tools & reinforcement learning from the existing tickets, product teams
can minimize service interruptions.
SLA management
i. Allows users to set, track, and manage SLAs to ensure that services are provided on
time.
Transparency
i. Requesters and engineers can view the accurate, current status of their requests and
tickets.
Risk management
i. Engineers can assign, analyze, and manage risks associated with an incident, problem,
or change.
Prioritize requests
i. Any incoming incident or service request will be assigned appropriate priority levels and
handled accordingly.
Self-service
i. End users can access solutions to common issues to fix problems themselves.
Reporting and metrics
i. Allow stakeholders to define and track important key performance indicators (KPIs) and
generate reports to assess overall help desk health.
o Manage the life cycle of incidents or service requests raised by end users.
Change management
Service level monitoring and management
Service catalogue
Knowledge base & Self-service capabilities
i. Allow users to resolve common issues on their own and reduce the help desk workload.
Asset management
i. Manage any documentation including screenshots, etc.
Reporting
End-user surveys
Key considerations for the solution
Help desk adds value by helping organization better manage customer experience. Here are some
key considerations while developing the solution:
•
Automation
i. Ticket creation
ii. Automatic escalation based on ticket types and SLAs
Automatically assign tickets to technicians
iv. Automated password reset service
v. Workflow automation
vi. Automatic notifications for requesters and technicians
Security
i. Role-based access permissions
ii. Secure communication with data encryption
iii. Audit logs
Single point of contact
i. An IT support ticket system converges all inbound communication and converts the help
desk into a single point of contact for all customer queries/ requests.
Centralization
i. All data, requests, queries, and tickets are centralized in one place, which makes it easier
to access and manage them.
Efficiency
i. With well-defined workflows and processes, help desk support software helps eliminate
redundant tasks and boosts efficiency.
Continuity
i. With the right tools & reinforcement learning from the existing tickets, product teams
can minimize service interruptions.
SLA management
i. Allows users to set, track, and manage SLAs to ensure that services are provided on
time.
Transparency
i. Requesters and engineers can view the accurate, current status of their requests and
tickets.
Risk management
i. Engineers can assign, analyze, and manage risks associated with an incident, problem,
or change.
Prioritize requests
i. Any incoming incident or service request will be assigned appropriate priority levels and
handled accordingly.
Self-service
i. End users can access solutions to common issues to fix problems themselves.
Reporting and metrics
i. Allow stakeholders to define and track important key performance indicators (KPIs) and
generate reports to assess overall help desk health.
iii. Automatically assign tickets to technicians
iv. Automated password reset service
v. Workflow automation
vi. Automatic notifications for requesters and technicians
Security
i. Role-based access permissions
ii. Secure communication with data encryption
iii. Audit logs
Single point of contact
i. An IT support ticket system converges all inbound communication and converts the help
desk into a single point of contact for all customer queries/ requests.
Centralization
i. All data, requests, queries, and tickets are centralized in one place, which makes it easier
to access and manage them.
Efficiency
i. With well-defined workflows and processes, help desk support software helps eliminate
redundant tasks and boosts efficiency.
Continuity
i. With the right tools & reinforcement learning from the existing tickets, product teams
can minimize service interruptions.
SLA management
i. Allows users to set, track, and manage SLAs to ensure that services are provided on
time.
Transparency
i. Requesters and engineers can view the accurate, current status of their requests and
tickets.
Risk management
i. Engineers can assign, analyze, and manage risks associated with an incident, problem,
or change.
Prioritize requests
i. Any incoming incident or service request will be assigned appropriate priority levels and
handled accordingly.
Self-service
i. End users can access solutions to common issues to fix problems themselves.
Reporting and metrics
i. Allow stakeholders to define and track important key performance indicators (KPIs) and
generate reports to assess overall help desk health.
Solution Approach
Manual ticket assigning and management creates inefficiencies & adds delays to issue resolutions. So,
we thought of addressing this issue using Machine Learning and build a platform which will automatically assign the ticket to the most appropriate teams or engineers and also has the ability to
learn and improve over time.
Model:
Multinomial Naive Bayes classification model would be the best fit for ticket classification.
Naive Bayes is a family of algorithms based on applying Bayes theorem with
the assumption, that every feature is independent of the others, in order to predict the
category of a given sample. They are probabilistic classifiers, therefore will calculate the
probability of each category using Bayes theorem, and the category with the highest
probability will be output.
We do have other alternatives when coping with NLP problems, such as Support Vector
Machine (SVM) and neural networks. However, the simple design of Naive Bayes classifiers
makes it very attractive for such classifiers. Moreover, they have been demonstrated to be
fast, reliable and accurate in a number of applications of NLP.
We would perform the following very common but crucial data pre-processing steps:
A. Lower case and removing stop words — Convert the entire input description to
lower case and remove the stop words as they don’t add any value to the
categorization
B. Lemmatizing words — This groups together different inflections of the same words
like organize, organizes, organizing, etc.
C. n-grams — Using n-grams we can count the sequence of the words, Instead of
counting single words
iv. Automated password reset service
v. Workflow automation
vi. Automatic notifications for requesters and technicians
Security
i. Role-based access permissions
ii. Secure communication with data encryption
iii. Audit logs
Single point of contact
i. An IT support ticket system converges all inbound communication and converts the help
desk into a single point of contact for all customer queries/ requests.
Centralization
i. All data, requests, queries, and tickets are centralized in one place, which makes it easier
to access and manage them.
Efficiency
i. With well-defined workflows and processes, help desk support software helps eliminate
redundant tasks and boosts efficiency.
Continuity
i. With the right tools & reinforcement learning from the existing tickets, product teams
can minimize service interruptions.
SLA management
i. Allows users to set, track, and manage SLAs to ensure that services are provided on
time.
Transparency
i. Requesters and engineers can view the accurate, current status of their requests and
tickets.
Risk management
i. Engineers can assign, analyze, and manage risks associated with an incident, problem,
or change.
Prioritize requests
i. Any incoming incident or service request will be assigned appropriate priority levels and
handled accordingly.
Self-service
i. End users can access solutions to common issues to fix problems themselves.
Reporting and metrics
i. Allow stakeholders to define and track important key performance indicators (KPIs) and
generate reports to assess overall help desk health.
Solution Approach
Manual ticket assigning and management creates inefficiencies & adds delays to issue resolutions. So,
we thought of addressing this issue using Machine Learning and build a platform which will automatically assign the ticket to the most appropriate teams or engineers and also has the ability to
learn and improve over time.
Model:
Multinomial Naive Bayes classification model would be the best fit for ticket classification.
Naive Bayes is a family of algorithms based on applying Bayes theorem with
the assumption, that every feature is independent of the others, in order to predict the
category of a given sample. They are probabilistic classifiers, therefore will calculate the
probability of each category using Bayes theorem, and the category with the highest
probability will be output.
We do have other alternatives when coping with NLP problems, such as Support Vector
Machine (SVM) and neural networks. However, the simple design of Naive Bayes classifiers
makes it very attractive for such classifiers. Moreover, they have been demonstrated to be
fast, reliable and accurate in a number of applications of NLP.
We would perform the following very common but crucial data pre-processing steps:
A. Lower case and removing stop words — Convert the entire input description to
lower case and remove the stop words as they don’t add any value to the
categorization
B. Lemmatizing words — This groups together different inflections of the same words
like organize, organizes, organizing, etc.
C. n-grams — Using n-grams we can count the sequence of the words, Instead of
counting single words

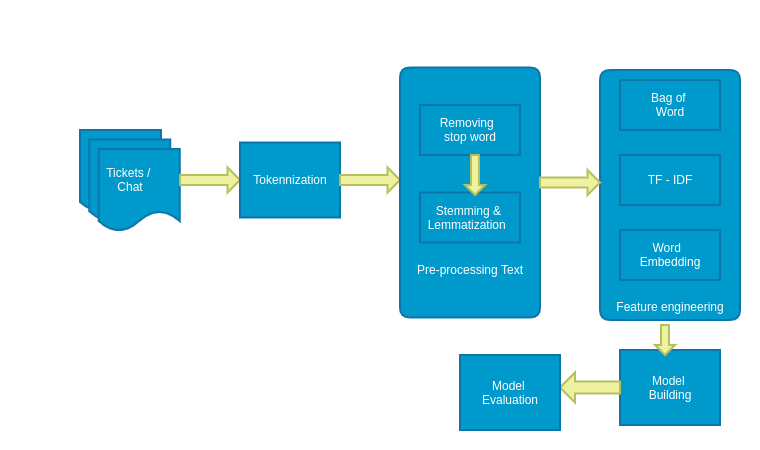
Multinomial Naive Bayes classification model would be the best fit for ticket classification.
Naive Bayes is a family of algorithms based on applying Bayes theorem with an
the assumption, that every feature is independent of the others, in order to predict the
category of a given sample. They are probabilistic classifiers, therefore will calculate the
probability of each category using Bayes theorem, and the category with the highest
probability will be output.
We do have other alternatives when coping with NLP problems, such as Support Vector
Machine (SVM) and neural networks. However, the simple design of Naive Bayes classifiers
makes it very attractive for such classifiers. Moreover, they have been demonstrated to be
fast, reliable and accurate in a number of applications of NLP.
We would perform the following very common but crucial data pre-processing steps:
A. Lower case and removing stop words — Convert the entire input description to
lower case and remove the stop words as they don’t add any value to the
categorization
B. Lemmatizing words — This groups together different inflexions of the same words
like organize, organizes, organizing, etc.
C. n-grams — Using n-grams we can count the sequence of the words, Instead of
counting single words
Naive Bayes is a family of algorithms based on applying Bayes theorem with an
the assumption, that every feature is independent of the others, in order to predict the
category of a given sample. They are probabilistic classifiers, therefore will calculate the
probability of each category using Bayes theorem, and the category with the highest
probability will be output.
We do have other alternatives when coping with NLP problems, such as Support Vector
Machine (SVM) and neural networks. However, the simple design of Naive Bayes classifiers
makes it very attractive for such classifiers. Moreover, they have been demonstrated to be
fast, reliable and accurate in a number of applications of NLP.
We would perform the following very common but crucial data pre-processing steps:
A. Lower case and removing stop words — Convert the entire input description to
lower case and remove the stop words as they don’t add any value to the
categorization
B. Lemmatizing words — This groups together different inflexions of the same words
like organize, organizes, organizing, etc.
C. n-grams — Using n-grams we can count the sequence of the words, Instead of
counting single words
This tutorial will help to find out the details about this ML model creation process:
https://towardsdatascience.com/real-time-it-support-ticket-classification-with-aws-
lambda-and-model-retraining-e4cb53814e9
https://towardsdatascience.com/real-time-it-support-ticket-classification-with-aws-
lambda-and-model-retraining-e4cb53814e9

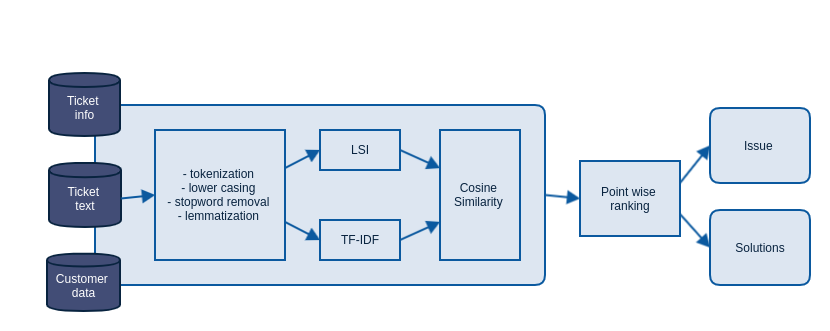
Core solutions with NLP and ML can be like above.



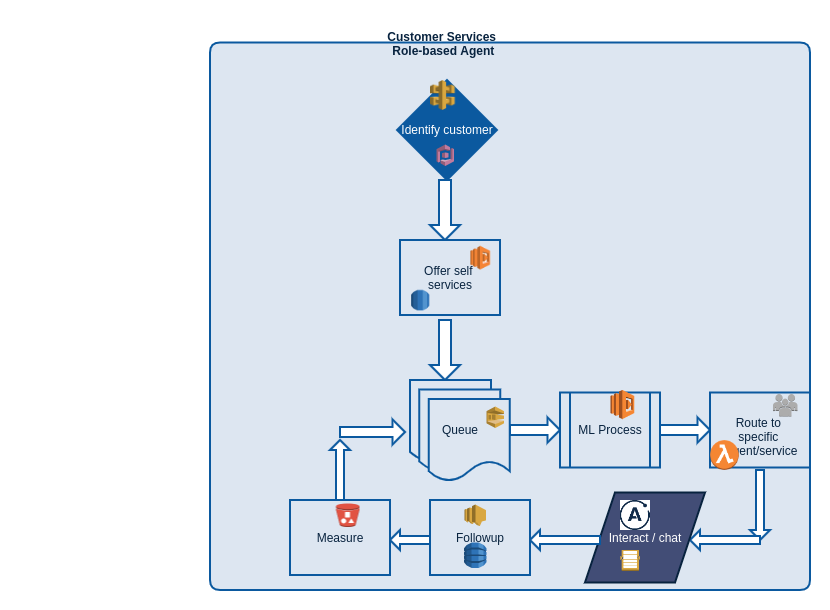
Basic services diagram
Sample — Primary Solutions structure
AWS Architecture for support solutions [High Level]
Every service [micro] will be implemented with the help of Lambda
• Main Menus can have the following services:
i. Knowledge Base or Self Services Help or Chatbot
ii. Live Chat
iii. Contact Us
iv. My Tickets
A. Ticket Log
B. Assigning Tickets
v. Live Support
A. Multiple Channel Support
B. Integration
C. File Attachment
D. Multilingual support if required
E. Customization
Sample — Primary Solutions structure
AWS Architecture for support solutions [High Level]
Every service [micro] will be implemented with the help of Lambda
• Main Menus can have the following services:
i. Knowledge Base or Self Services Help or Chatbot
ii. Live Chat
iii. Contact Us
iv. My Tickets
A. Ticket Log
B. Assigning Tickets
v. Live Support
A. Multiple Channel Support
B. Integration
C. File Attachment
D. Multilingual support if required
E. Customization

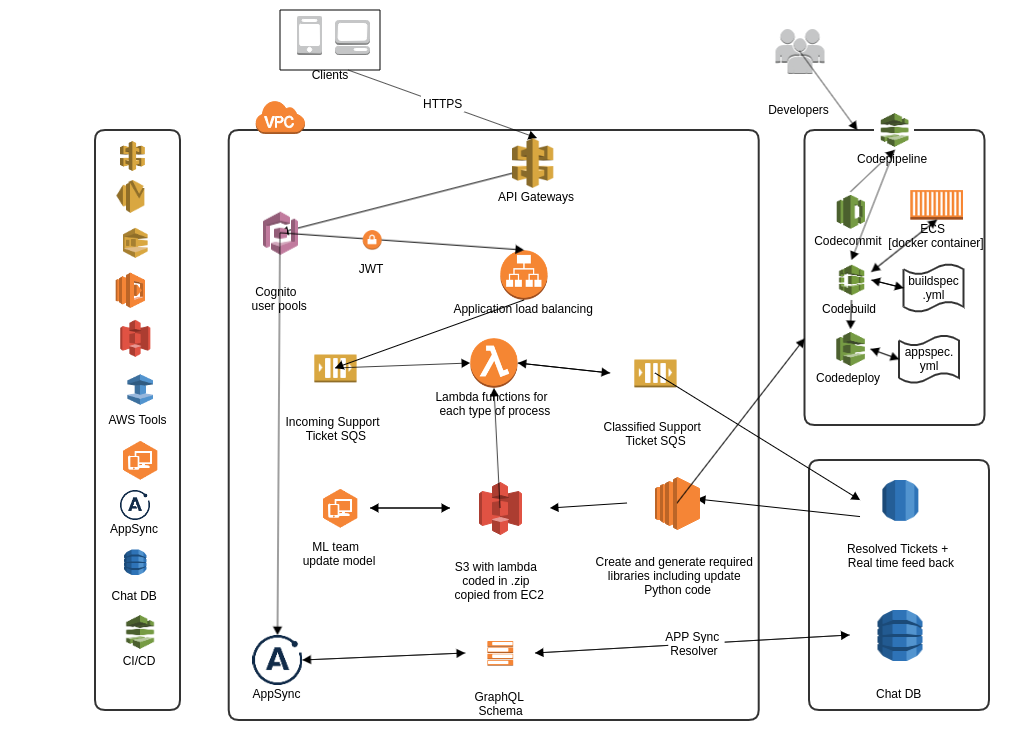
Proposed core IT Structure to be in AWS
• Centralized database of end user details, tickets, workstation history, and resolution tools.
• History of all tickets and actions performed on them, along with technician details.
• Repository of solutions in a knowledge base.
• Automated workflows and processes.
• Real-time notifications about requests and tickets.
• Multi-tier organized help desk architecture.
• KPI tracking and measurement.
Core IT structure would be following
• Centralized database of end user details, tickets, workstation history, and resolution tools.
• History of all tickets and actions performed on them, along with technician details.
• Repository of solutions in a knowledge base.
• Automated workflows and processes.
• Real-time notifications about requests and tickets.
• Multi-tier organized help desk architecture.
• KPI tracking and measurement.
Core IT structure would be following

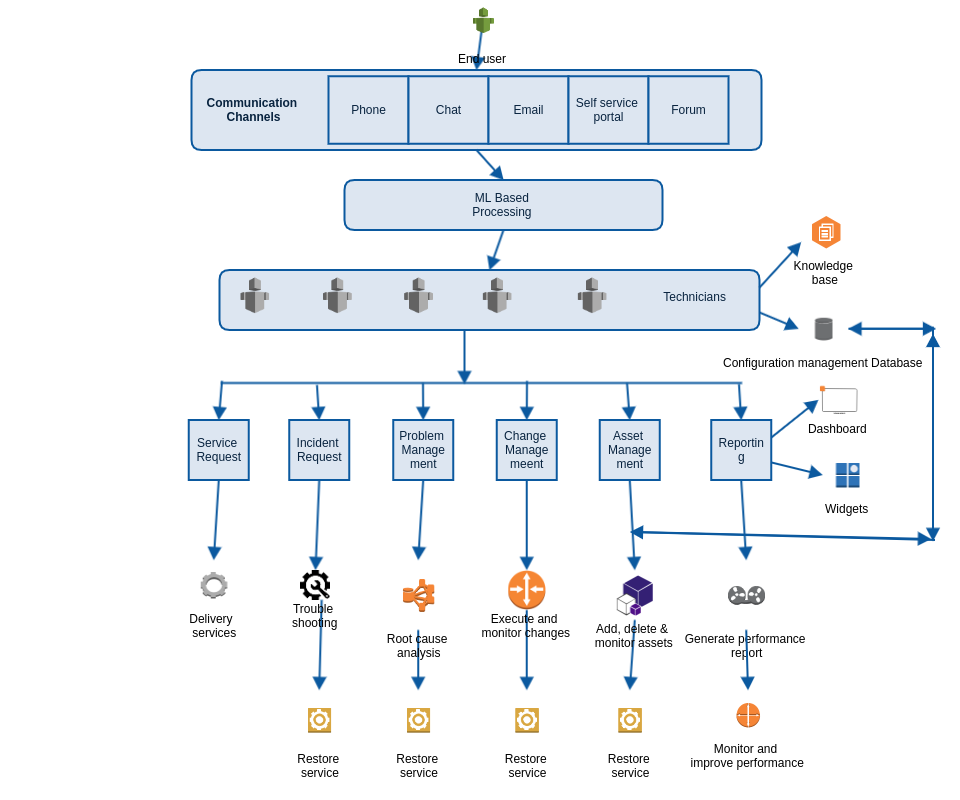
NOTE: We have to analyse the current ticketing systems, apps (mobile, web) to understand the
possibility for integrations.
possibility for integrations.



